|
Qorus Integration Engine® Enterprise Edition 6.0.16_prod
|
|
Qorus Integration Engine® Enterprise Edition 6.0.16_prod
|
Back to the Developer's Guide Table of Contents
Each Qorus interface (meaning workflows, services, and job) has a Qore-language Program object that manages its logic. Qorus workflow logic can also be written in Python and Java, however this is managed from the workflow's Qore Program object in any case.
All Qorus integration objects are described by YAML metadata produced by our IDE, which is available as a free (as in free of charge and also open source) extension to Microsoft Visual Studio Code, a multi-platform editor from Microsoft. The Qorus extension is called Qorus Developer Tools and can be installed directly from Visual Studio Code.
Workflows are made up a set of interdependent steps that each perform one traced and restartable action. To design a workflow, a series of logical steps and their dependencies must be defined and then represented by a workflow definition file. Once the high-level design for the workflow has been done, then the logic for the steps can be implemented and the workflow definition and the functions can be loaded into the database and executed.

The following table defines the major elements used when designing and implementing an Qorus workflow.
Qorus Workflow Elements
| Element | Description |
| Step | The lowest element in a workflow, represents one traced and restartable action. Each step is defined by at least primary step code containing the logic for the step, and optionally other code attributes (such as validation code, run when the step is run in error recovery mode, or asynchronous back-end code, required for asynchronous steps) and other option attributes. |
| Workflow | The workflow is the highest level element defining the logic as a set of steps and inter-step dependencies, along with other attributes; workflows process workflow order data instances that in turn contain the data and the status of processing (status of all steps). A running workflow is called a workflow execution instance and can be run either in batch mode (OMQ::WM_Normal), batch recovery mode (OMQ::WM_Recovery), or synchronous mode. |
| Queue | Asynchronous steps require a queue for linking the associated step data created by the front-end logic with the back-end code. |
| Workflow Synchronization Events | Workflow synchronization event steps allow multiple workflow orders to synchronize their processing based on a single event |
Workflows process workflow order data in atomic steps. Steps have dependencies; a step can only execute if all previous steps that the step depends on have a COMPLETE status.
When a single step has multiple steps that depend on it directly, each of those steps will be executed in parallel.
Consider the following diagram:

In this diagram, as soon as step TelcoCreateBillingAccount has a COMPLETE status, the TelcoActivateTechnicalServices and TelcoRegisterCounterFraud account will be executed in parallel in separate threads. When both of those steps have a COMPLETE status, then the TelcoUpdateCrmAccount step is executed.
Therefore, to plan for workflow steps to execute in parallel, place more than one step as a direct dependency of another step. Each of these steps will be executed in parallel. This can continue to any level, and there is no predefined limit on parallelism in Qorus workflows.
Qorus includes a framework for defining error information and raising errors. If a workflow defines workflow- specific errors, oload loads the error information the system database in the GLOBAL_WORKFLOW_ERRORS and WORKFLOW_ERRORS tables (see Global and Workflow-Specific Error Definitions for more information). Each error definition a hash describing how the system should act when certain errors are raised when processing workflow order data.
Workflows raise errors by throwing an unhandled exception or by calling one of the following APIs:
In the case an exception is thrown, for Python exceptions, the exception err value is the exception class name ("socket.timeout"); for Java exceptions, the exception full class name (ex: "javax.xml.soap.SOAPException") is used as the error name; for Qore exceptions, the exception err code is used as the error name; the system will then use the error name as the hash key to look up error information to handle the error.
To allow a workflow to recover gracefully from an error, implement validation code for each step. Validation code allows workflows to recover gracefully from errors such as lost request or response messages or temporary communication failures without requiring manual intervention.
By default, error definitions are global. A global definition is a workflow error definition that applies to all workflows. Workflow-specific error definitions apply only to a particular workflow configuration.
There are three ways to create workflow-specific error definitions:
"level" = OMQ::ErrLevelWorkflow in the errorfunction's return value"level" key unassigned (or assigned to the default: OMQ::ErrLevelAuto) in the errorfunction's return value but give the error a different definition than an existing global errorThe last point above implies that if two or more workflows define the same error with different attributes (but leave the error's "level" option either unset or assigned to the default: OMQ::ErrLevelAuto), the first error will be a global error, and each time the other workflows define the error with a different set of attributes, those new errors will be workflow-specific error definitions.
Qorus includes default error definitions for common technical errors that should normally result in a workflow order instance retry and also template errors that can be re-used in workflows as needed.
To get a complete list of error definitions, issue the following command from the command line:
qdp omq/workflow_errors search
See the Qorus web UI's "Global Errors" page or the detail page for each workflow to see how error's are configured in Qorus as errors may have been redefined or overridden after the initial installation.
GLOBAL_WORKFLOW_ERRORS tableWorkflows and steps, along with almost every other object in the Qorus schema, are versioned. When a new version of a workflow is released, either due to a logic upgrade or a bug fix, keep in mind that workflows can only recover data that has been processed by the same version of that workflow.
EXAMPLE-WORKFLOW 1.1 cannot recover data processed by EXAMPLE-WORKFLOW 1.0. Furthermore, example-step 1.1 cannot recover data processed by example-step 1.0.When it is necessary to maintain recovery compatibility in a workflow update, then it will be necessary to redefine steps and workflows with the same version name and number. In these cases, the patch attribute of the object should be updated to reflect the change.
Also keep in mind that new steps added to a workflow will be executed for data that is being recovered even with data that was initially processed by a previous version of the workflow that did not include the new step in its definition.
If a step is removed from a workflow and data must be recovered where that step has a OMQ::StatRetry status, then that data cannot be recovered by a definition of the workflow that no longer includes that step.
These points should be considered carefully when planning workflow updates.
Sometimes it may be necessary to release two or more versions of a workflow when changes must be made; for example one version to make a bug fix in an existing version, and a new version with additional or removed steps also including the bug fix.
Because a running workflow execution instance can be working on several different orders at once in different threads, accessing workflow data is performed through API calls in order to guarantee that the workflow's program code accesses only the correct data for the current order being processed at all times.
Accessing and processing data is done using the Qorus API as outlined in this section; these APIs set up the data context for each thread so that the correct data is accessed.
Static data represents the workflow order data being processed. Workflow static order data cannot be updated or deleted by the Qorus workflow API; it is read-only data representing the order data to be processed or fulfilled by the workflow.
APIs:
The information returned by the above function corresponds to the deserialized contents of the field ORDER_INSTANCE.STATICDATA.
Dynamic data is associated with the workflow order data instance being processed, but it can be updated and is persistent. Any changes made to dynamic data will be committed to the database before the update method returns, therefore any changes will be available in the future, even in the case of errors and later recovery processing.
Dynamic data is appropriate for storing identifiers and references generated during order processing that are needed in subsequent steps, for example.
Python API support:
Java API support:
Qore API support:
Dynamic step data, like dynamic order data is associated with the workflow order data instance and also the current step being processed, additionally it can be updated and is persistent like dynamic order data. Any changes made to dynamic step data will be committed to the database before the update method returns, therefore any changes will be available in the future, even in the case of errors and later recovery processing.
Dynamic step data is appropriate for storing information specific to a particular step, particularly user-driven form data with asynchronous steps with the user-interaction flag enabled.
Python API support:
Java API support:
Qore API support:
REST API support:
Qorus maintains a hash of temporary data associated to the workflow order data instance being processed. This hash can be updated, but it is not persistent, therefore this hash is suitable for temporary data storage only.
This data is lost every time Qorus detaches (i.e. temporarily or permanently stops processing a workflow order data instance, for example, due to an ERROR status and purges the data from the workflow data cache) from a workflow order data instance.
Because temporary data is deleted every time Qorus detaches from a workflow order data instance, it can only be reliably set in the attach logic.
Python API support:
Java API support:
Qore API support:
Qorus was designed to allow workflow sensitive order data to be processed while avoiding inadvertent disclosure of this data to unauthorized persons.
Workflow sensitive order data must be processed separately for each data subject stored against the workflow order, this is because each data subject's sensitive data can be queried, updated, or deleted separately across all workflow orders in the system (both in the system schema and any archiving schema).
Workflow order sensitive data is stored separately for each data subject against the workflow order using two identifiers as follows:
skey: the sensitive data key type (not treated as sensitive itself, ex: "tax_id", "social_insurance_nr", "ssn", etc)svalue: the sensitive data key value, which is also treated as sensitive itselfThe following image provides an overview of a concrete example of sensitive data stored against a workflow order storing sensitive data for at least two data subjects with tax_ids "984.302192.AF" and "739.323.714.BR":

The svalue value, being sensitive itself, should not be stored in static, dynamic data, or step dynamic data. To reference sensitive data from within non-sensitive data, an alias can be used, which is a unique identifier within a workflow order that can be used to uniquely identify sensitive data for a single data subject. Sensitive data aliases are only usable in internal sensitive data APIs.
For example, if a workflow order consists of non-sensitive order information along with a natural person's name and address (which is sensitive) for each order, then the sensitive data alias could simply be the list index (ex: "0", "1", ...).
The following internal workflow APIs provide sensitive data support:
Python APIs:
Java APIs:
Qore APIs:
Workflow execution instance data is stored in a hash maintained by the system. This data is local to the running workflow execution instance pseudo-process and persists until the workflow execution instance terminates.
Any changes made to this data will persist within the running workflow execution instance (pseudo-process) independently of the workflow order data processed.
Because of this, workflow execution instance data is a substitute for global variables in a workflow program. Workflow programs are shared between all running workflow execution instances of that same type (sharing the same name and version and the same workflowid); global variables are not allowed because it is considered unsafe for workflow execution instances to share any common state. If your workflows do need to share some data between execution instances, implement a Qorus service to provide this functionality instead.
Workflow execution instance data will be set in the onetimeinit code (initializing resources for the workflow execution instance), and read by the rest of the workflow.
Python methods:
Java methods:
Qore methods:
The following properties of the workflow metadata can be returned by the following APIs:
Workflow Metadata
| Key | Description |
name | name of the workflow |
version | version of the workflow |
patch | The patch attribute of the workflow |
workflowid | ID of the current workflow (metadata ID) |
remote | a boolean value giving the remote status of the workflow (if it is running as an independent process or not; see the remote flag) |
description | The description of the workflow |
cached | The date and time the workflow metadata was read and cached from the database |
errorfunction_instanceid | The function instance ID of the error function of the workflow |
attach_func_instanceid | The function instance ID of the attach function for the workflow |
detach_func_instanceid | The function instance ID of the detach function for the workflow |
onetimeinit_func_instanceid | The function instance ID of the onetimeinit function for the workflow |
errhandler_func_instanceid | The function instance ID of the error handler function for the workflow |
keylist | A list of valid order keys for the workflow |
errors | The error hash as returned from the error function |
options | A hash of valid workflow options, key = option, value = description |
Properties of the current running workflow execution instance can be retrieved via the following APIs:
Running Workflow Execution Instance Properties
| Key | Description |
dbstatus | the status of the workflow order in the database (for the current status, see the status key, see Workflow, Segment, and Step Status Descriptions for possible values); this will normally be OMQ::StatInProgress, unless called from the Workflow Class Detach Method (first available in Qorus 2.6.2) |
external_order_instanceid | The external order instance ID saved against the order, if any |
execid | the execution instance ID (workflow pseudo-process ID, first available in Qorus 2.6.0.3) |
initstatus | the status of the workflow when it was cached (before it was updated to OMQ::StatInProgress, see Workflow, Segment, and Step Status Descriptions for possible values); note that synchronous workflow orders are created with status OMQ::StatInProgress, so initstatus should always be OMQ::StatInProgress for synchronous orders |
instancemode | The mode the workflow execution instance process is running in (OMQ::WM_Normal or OMQ::WM_Recovery) |
mode | The mode the current thread is running in (OMQ::WM_Normal or OMQ::WM_Recovery) |
remote | a boolean value giving the remote status of the workflow (if it is running as an independent process or not; see Workflow Remote Parameter) |
sync | True if the workflow execution instance is synchronous, False if not |
name | name of the workflow |
parent_workflow_instanceid | The workflow order data instance ID of the parent workflow if the current workflow order is a subworkflow, NOTHING if not |
priority | The priority (0 - 999) of the workflow order data instance (first available in Qorus 2.6.0.3) |
started | The date/time the workflow order data instance was created (first available in Qorus 2.6.0.3) |
status | The current status of the workflow order data instance (see Workflow, Segment, and Step Status Descriptions for possible values); this will normally be OMQ::StatInProgress; first available in Qorus 2.6.2) |
version | version of the workflow |
workflowid | ID of the current workflow (metadata ID) |
workflow_instanceid | The current workflow order data instance ID being processed |
Qorus workflows should always target comprehensive error recoverability, so that workflows can handle any recoverable error by design, meaning that, assuming that the input data are correct and that end systems and network transports are available (or become available within the retry period(s) defined by the workflow and server settings), the workflow will complete successfully even in case of errors.
The following sections describe the design and implementation constraints for a workflow to meet these requirements, the common errors that must be dealt with, and how to deal with them.
The following are some examples of conditions that must be addressed for a workflow to meet comprehensive error recoverability requirements:
This section describes some possible error conditions necessitating the requirements in the previous section.
By designing and implementing your workflows to the requirements in the previous section, the error conditions above can be covered with no data loss. The following conditions apply principally to Requirement 3 above.
These cases can be recognized by a communications failure (normally an exception) or a message timeout.
In either case, if the workflow's logic cannot determine if the message was processed by the end system before the failure, and the action can only be performed once for the input data in the end system in question, then the error defined by the workflow should have a OMQ::StatRetry status, and validation code must be defined that will check the end system to see if the action was carried out or not.
This can happen, for example, if an HTTP message (or other network message) is sent and a timeout occurs. The timeout could have happened because the message was never received, the message was received and processed, and the response message was lost, or the message was received and an error happened while processing the message that prohibited the response from being sent.
Because this information is critical to the further processing of the workflow/order data, the programmer must define validation code to the step object that will verify the status of the action in the end system before continuing when the step is recovered by Qorus.
A validation code should be used instead of handling the error in the step logic itself, because the problem that caused the error could prohibit the validation code from being run successfully (for example with a temporary network outage or an end-application restart). As the validation code is run after the recovery delay (see system options qorus.recover_delay and qorus.async_delay), the chances of successfully determining the status are higher than with trying to handle the error in the step logic itself.
While hardly a common problem, Qorus has been designed so that recovery from a system crash (power outage, database outage, etc) is recoverable as long as the database remains consistent (the system schema must be recovered to a consistent state).
The Qorus database should always be in a clustered or high-availability configuration in order to ensure database consistency. Qorus's internal design is such that catastrophic failures such as a power failure on the system hosting the Qorus application can always be recovered to a consistent state and will allow properly-designed workflows to be recovered.
When Qorus recovers a crashed application session, all steps that were OMQ::StatInProgress are set to OMQ::StatRetry. When they are retried, if each step that requires validation code (for example, a non-repeatable step in an end-system) has one, then the workflow can ensure that it can always recover at any point from an Qorus system failure.
Workflow definition files define workflow metadata including the steps and dependencies between steps.
Workflow definition files are defined in YAML.
Workflows files define the following properties:
The name of the workflow; the name and version together are unique identifiers for the workflow and are used to derive the workflowid (the single unique identifier for the workflow; it is generated from a database sequence when the workflow is loaded into the system via oload).
Mutiple workflows with the same name and different versions can exist in the system at the same time. Workflows are referred to with their workflowid, which is derived from the name and version together.
The version of the workflow; the name and version together are unique identifiers for the workflow and are used to derive the workflowid (the single unique identifier for the workflow; it is generated from a database sequence when the workflow is loaded into the system via oload).
Mutiple workflows with the same name and different versions can exist in the system at the same time. Workflows are referred to with their workflowid, which is derived from the name and version together.
The description of the workflow; accepts markdown for formatted output.
The "author" value indicates the author of the workflow and will be returned with the workflow metadata in the REST API and also is displayed in the system UI.
The "remote" flag indicates if the workflow will run as an independent qwf process communicating with other elements of Qorus Integration Engine with a distributed queue protocol rather than internally in the qorus-core process.
When workflows run in separate qwf processes, it provides a higher level of stability and control to the integration platform as a whole, as a workflow with implementation problems cannot cause the integration platform to fail.
There is a performance cost to running in separate qwf processes; workflow startup and shutdown is slightly slower, and communication with qorus-core also suffers a performance hit as all communication must be serialized and transmitted over the network.
Furthermore memory usage is significantly higher for interfaces running in separate programs, as all the common infrastructure for each interface must be duplicated in each process.
The default for this option depends on the client option qorus-client.remote (if this client option is not set, then the default value is True).
The remote value can be changed at runtime by using the following REST API: PUT /api/latest/workflows/{id_or_name}?action=setRemote
remote flag is considered to be managed by operations, which means that once an interface has been loaded into Qorus, if its remote flag is updated with the API, then those API-driven changes are persistent and will not be overwritten by subsequent loads of the interface by oload.The workflow "autostart" parameter sets the number of workflow execution instances to be started when the system is started; if the system should ensure that this workflow is generally running, then set this key to a value greater than zero.
If no value is provided for this option, the system will not start the workflow automatically; any workflow execution instances for this workflow must be started manually.
If a non-zero value is provided for this workflow, then the system will attempt to start the workflow at all times if all its dependencies are met, and it is not disabled. Additionally, if the workflow cannot be started for any reason (for example, due to an error in the onetimeinit logic or a dependency error), an ongoing system alert will be raised, which is only cleared when the workflow is successfully started (or the autostart parameter is set to zero).
"autostart" value is considered to be managed by operations, which means that once a workflow has been loaded into Qorus, if its "autostart" value is updated with the API, then those API-driven changes are persistent and will not be overwritten by subsequent loads of the workflow by oload.The workflow "sla_threshold" parameter sets the amount of time as an integer in seconds in which each workflow order should get a final status, where a final status is defined as either COMPLETE or CANCELED; if not present the default value of 30 minutes is assumed (see DefaultWorkflowSlaThreshold).
This value is used to do SLA reporting for workflow orders in the REST and WebSocket APIs.
"sla_threshold" value is considered to be managed by operations, which means that once a workflow has been loaded into Qorus, if its "sla_threshold" value is updated with the API, then those API-driven changes are persistent and will not be overwritten by subsequent loads of the workflow by oload.The optional "max_instances" key sets the maximum number of workflow execution instances that can be running at one time; note that workflow execution instances are capable of processing up to two orders in parallel at any one time: one in "normal" mode and one in recovery mode.
To serialize workflow processing and ensure that only one order is processed at one time at any particular point in the workflow's logic, set the "max_instances" value to 1, and use the synchronized keyword on a function or method called in both normal and recovery mode, or make a service call to a service method that uses threading primitives to ensure atomicity of operation (or has the service method write lock flag set).
If workflow options are defined in the workflow definition, the workflow will advertise and accept only the options defined as valid options for the workflow (aside from system options that can be overridden at the workflow level, which are always accepted as workflow options).
Valid options are stored in the YAML file as a hash where the hash keys are the option names, and the values assigned to the keys are the descriptions of the options.
Workflows can declare type enforcement for static data in the IDE; if defined, this will be enforced whenever workflow order data is created.
If the static data type is defined, and a workflow order is attempted to be created with static data that is not accepted by the type, an ORDER-DATA-ERROR exception is thrown.
Workflow order keys can be used both for quick identification and lookup of order data and can also be used to enforce uniqueness of orders with varying granularity (system-wide, workflow-specific, or workflow-version-specific uniqueness).
In order to set a workflow order key against a workflow, the valid keys must be defined in this list.
Any number of workflow keys may be given in the workflow definition, in contrast to the single external_order_instanceid that can be given at the workflow order data instance object level and can also be used for the same purpose (quickly looking up workflow order data instances from a external key).
Keys can be set and retrieved by the following APIs:
Key metadata is saved in the WORKFLOW_KEYS table, and workflow order data instance keys are saved in the ORDER_INSTANCE_KEYS table. Note that a single key value can be saved for more than one workflow order data instance; the indexes on the ORDER_INSTANCE_KEYS only enforce that values may not be repeated for the same workflow_instanceid and key name.
The REST API provides methods to lookup workflow orders by workflow keys; see the following API for more information:
Qorus workflows can declare a workflow class that defines workflow-level code. The "class-name" attribute defines the name of the class that will be used for the workflow. The class must inherit the workflow base class for the programming language used as described below.
Python workflow base class:
Java workflow base class:
Qore workflow base class:
This attribute provides a list of Qore-language modules that are loaded in the workflow's logic container that can provide base classes for the workflow class, step classes, or other functionality for the workflow.
Workflows cannot declare configuration items because workflows are just a set of steps. Instead it's allowed to set the value of a step configuration item on the workflow level at runtime using the operational web UI or the REST API.
All Qorus integration objects are described by YAML metadata produced by our IDE, which is available as a free (as in free of charge and also open source) extension to Microsoft Visual Studio Code, a multi-platform editor from Microsoft. The Qorus extension is called Qorus Developer Tools and can be installed directly from Visual Studio Code.
The IDE allows step metadata to be defined as well as the step's code if required; steps relying solely on building blocks and/or with their implementation in one or more finite state machines or implemented using class connection do not require any additional code.

The following diagram illustrates a subset of the attributes of a step that can be defined.
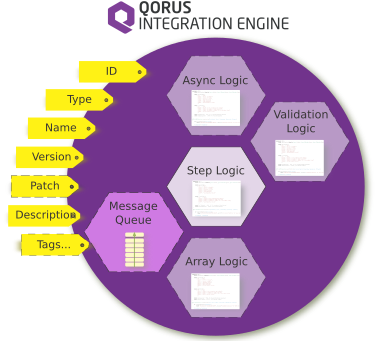
Note that each logic attribute is defined by a step class, and the step ID is not assigned in the workflow definition file, but rather by the loader (oload).
Steps have the following attributes:
The name of the step; the name and version together are unique identifiers for the step and are used to derive the stepid (the single unique identifier for the step; it is generated from a database sequence when the step is loaded into the system via oload).
Mutiple steps with the same name and different versions can exist in the system at the same time. Steps are referred to with their stepid, which is derived from the name and version together.
The version of the step; the name and version together are unique identifiers for the step and are used to derive the stepid (the single unique identifier for the step; it is generated from a database sequence when the step is loaded into the system via oload).
Mutiple steps with the same name and different versions can exist in the system at the same time. Steps are referred to with their stepid, which is derived from the name and version together.
A string "patch" label which can be used to show that a step was updated while not affecting the stepid.
patch value can be updated without affecting references to other objects; the unique ID for the object is not updated when the patch value is updatedA description for the step; the description field supports markdown for formatted output in the UI and IDE.
The "author" value indicates the author of the step and will be returned with the step metadata in the REST API and also is displayed in the system UI.
Steps support library objects that provide additional code for the step.
An optional list of mappers that are used in the step.
An optional list of value maps that are used in the step.
True, then the asynchronous step will support APIs for user interaction; can only be set on asynchronous steps. If this key is not present in the step definition, the default value is False.The programming language used for the step implementation.
The Qorus IDE allows for editing the source code for a step as well as editing the step's metadata.

The step's logic is defined as a class that inherits one of the following step classes:
Step Classes per Step Type
| Step Type | Step Class |
| Asynchronous Steps | Python / Java / Qore: QorusAsyncStep |
| Workflow Synchronization Event Steps | Python / Java / Qore: QorusEventStep |
| Normal Steps | Python / Java / Qore: QorusNormalStep |
| Subworkflow Step | Python / Java / Qore: QorusSubworkflowStep |
| Array Asynchronous Steps | Python / Java / Qore: QorusAsyncArrayStep |
| Array Workflow Synchronization Event Steps | Python / Java / Qore: QorusEventArrayStep |
| Array Normal Steps | Python / Java / Qore: QorusNormalArrayStep |
| Array Subworkflow Step | Python / Java / Qore: QorusSubworkflowArrayStep |
The step's class determines its type as given in the above table.
Class-based steps can have a constructor and classes can have static initialization, but please note that if the step has configuration items, it must be instantiated by oload in order to validate the workflow's logic and in some cases to create the step's configuration in the system. In such a case, if the constructor or static class initialization requires features that are only available at runtime in Qorus itself, the errors raised will cause step class instantiation or static class instantiation to fail.
The step constructor takes no arguments.
Queues provide the storage and delivery mechanism by which the results of executing an asynchronous event for an asynchronous step are delivered to the right step instance.
Each asynchronous step in a workflow must be associated to a queue (although in theory all the asynchronous steps can use the same queue if desired).
A single queue can be used for any number of asynchronous steps, however the keys in a queue must be unique.
The step queue value must be set to a string giving the name of the queue for asynchronous steps. The queue will link the asynchronous step's primary step code with the back-end code.
When the result of the asynchronous action is available, the result must be posted to the step's queue using the key created in the step's primary step code when one of the following methods is called, depending on the language used:
The queue will hold this data (stored in the database table QUEUE_DATA) and pass it to the asynchronous back-end code in order to determine the step's status.
See Asynchronous Queue Objects for more information.
A workflow synchronization event step must be associated with a workflow synchronization event type, and therefore an attribute providing a valid value of this type is required for this kind of step.
During step execution, the step must be bound to a workflow synchronization event by calling one of the following APIs:
Alternatively, in case the step should not bind itself to a workflow synchronization event, one of the following APIs can be called instead:
If none of these APIs are called in the step's primary step code, the step will exit with an error. Otherwise, if a workflow synchronization event is bound to the step, the step will only receive a COMPLETE status when the event is posted.
Workflow synchronization events can be posted with the following APIs:
The value of the tag must be the name of a valid workflow synchronization event.
Steps can also provide user-defined metadata which is returned as part of the step's metadata description.
This information can be used by internal Qorus code, external programs, or web pages (for example) to control user interactions related to the step (among other uses).
Steps can declare configuration items as metadata to allow for the behavior of the step to be modified by users at runtime using the operational web UI or the REST API.
Step configuration items are:
Step configuration items are designed to allow users to affect the execution of a step so that changes can be made by authorized users in the UI without requiring a change to development.
If the strictly_local flag is True, then the step configuration item is local and the value for the configuration item cannot be set on the workflow or the global level.
If the strictly_local flag on a step configuration item is False (the default), then the step configuration item is not local and the value can also be set on the workflow or the global level.
strictly_local flag set to False; use the following REST API to retrieve step configuration items in the context of its declaring workflow: GET /api/latest/workflows/{id_or_name}/stepinfo/{id_or_name}/config/{name}Steps support library objects in way similar to workflows, services, and jobs, however step library objects are loaded into the workflow's program container.
Library objects for steps can only be defined in YAML step definition file (for more details see Implementing Qorus Objects Using YAML format).
A normal step is a step that is not a subworkflow, asynchronous, or workflow synchronization event step. Normal steps do not have asynchronous back-end code, a queue, or a workflow synchronization event type and cannot be used as a subworkflow step.
A normal step may be an array step, which would make it a normal array step.
The base step classes to be inherited by normal step classes are:
Python / Java / Qore classes:
See the documentation for the classes above for example step definitions.
array trigger for the array() method for array stepsprimary trigger for the primary() methodvalidation trigger for the validation() methodA subworkflow step binds a child workflow (called a subworkflow) to a step. The child workflow's status will be bound to the step's status; that is; whatever status the child workflow has will be reflected as the step's status. This is how Qorus supports logical branching in workflows, where one branch of processing is optionally executed based on a logical condition.
The base step classes to be inherited by subworkflow step classes are as follows.
Python / Java / Qore classes:
See the above classes for example step definitions.
Subworkflow steps are not bound to any particular workflow type; the only rule for a subworkflow step is that one of the following API calls must be made in the primary step code for the steps.
FSM / Flow API for API Call States:
Python and Java methods:
Qore methods:
A subworkflow step may be an array step, which would make it a subworkflow array step.
array trigger for the array() method for array stepsprimary trigger for the primary() methodData can be passed from subworkflows back to the parent as workflow feedback.
Asynchronous steps allow Qorus to efficiently process asynchronous actions. In the context of Qorus workflow processing, asynchronous actions are actions that may take a significant amount of time to complete. It is not necessary to know in advance how much time the action will take to complete to define an asynchronous step.
The base step classes to be inherited by asynchronous step classes are as follows.
Python / Qore classes:
See the above classes for example step definitions.
To define an asynchronous step, the step definition must define asynchronous back-end code and a queue, and one of the following API calls must be made during the execution of the primary step code.
FSM / Flow API for API Call States:
Python methods:
Java methods:
Qore methods:
The methods listed above save a reference to the step's action as a unique key in the namespace of the queue; all keys submitted to a queue of the same name must be unique (this is enforced by an index in the Qorus database).
The system option qorus.async_delay determines when the system will retry the step if the step's queue has not been updated in time. If there is no validation code, the default behavior for the system will be to delete any queue data for the step, and re-run the step's primary step code. If this is not the desired behavior, then you must implement validation code to control how the system reacts to an asynchronous timeout.
When the result of the asynchronous action is available, code external to the workflow must update the queue entry using a supported API that identifies the queue entry with the queue's name and the unique key in the queue; any data posted to the queue entry is passed to the step's back end logic.
Often asynchronous updates are enabled by implementing a Qorus service to monitor the result of asynchronous processing that then updates the queue entry to enable processing to continue for the affected order.
Within Qorus, the following is an example of how to call the REST API POST /api/latest/async-queues/{queue}?action=update from a Qorus service; in this example, a table in an external database is polled by checking which queue entries are still outstanding by calling GET /api/v3/async-queues/{queue}?action=qinfo and then updated with POST /api/latest/async-queues/{queue}?action=update.
An asynchronous step may be an array step, which would make it an asynchronous array step.
Asynchronous steps define a segment discontinuity; all normal steps leading up to the asynchronous step are in the same segment; and all normal steps executed after the asynchronous step are in another segment. Qorus workflow segments are each processed in their own thread and can process workflow order data instances independently of one another.
array trigger for the array() method for array stepsend trigger for the end() methodprimary trigger for the primary() methodvalidation trigger for the validation() methodWorkflow synchronization event steps allow many workflow orders to synchronize their processing based on a single event. A workflow synchronization event step may be an array step, which would make it a workflow synchronization event array step.
The base step classes to be inherited for asynchronous step classes are as follows.
Python / Java / Qore classes:
See the above classes for example step definitions.
The primary step code for a workflow synchronization event step must make one of the following API calls:
The step definition must reference a workflow synchronization event type as well; event keys bound or posted are treated unique within their event type. Additionally, workflow synchronization event steps may not have validation code.
array trigger for the array() method for array stepsprimary trigger for the primary() methodAny type of step can be an array step. An array step is any step that may need to repeat its action more than once. Any step type can be an array step; normal, asynchronous, subworkflow, or workflow synchronization event steps can be array steps. The difference between a non-array step is that array steps have an array method, and the argument signature also changes for other step methods.
The recommended way to define steps is by defining all the step's logic as a subclass of one of the following step classes:
Array Step Classes per Step Type
| Step Type | Base Step Class |
| Array Asynchronous Steps | Python / Qore / Java: QorusAsyncArrayStep |
| Array Workflow Synchronization Event Steps | Python / Qore / Java: QorusEventArrayStep |
| Array Normal Steps | Python / Qore / Java: QorusNormalArrayStep |
| Array Subworkflow Step | Python / Qore / Java: QorusSubworkflowArrayStep |
See the above classes for example step definitions.
The return value of the array code will determine how many times the step will execute, and on what data. Please note that array steps have different code signatures, as the array element is always passed to the step logic code (primary step code, validation code, and asynchronous back-end code for asynchronous steps).
array trigger for the array() method for array stepsprimary trigger for the primary() methodvalidation trigger for the validation() methodfuncname key, or, if this is not present, the name of the step is assumed to be the name of the primary step code as well.Every step base class has an abstract primary() method where the primary step logic must be defined. See the class documentation for the specific step class for more information on requirements for the primary step method.
primary trigger, the primary() method will never be executed, and the method body should remain empty.primary() method for array steps can be accessed as finite state machine input data:
The following table describes how the system reacts depending on the return value of the validation logic.
Validation Code Return Value
| Return Value | System Behavior |
| OMQ::StatComplete | Do not run the primary step logic; mark the step as COMPLETE and continue. For asynchronous steps, back-end code also will not be run |
| OMQ::StatError | Do not run the primary step logic; mark the step as ERROR and stop running any further dependencies of this step |
| OMQ::StatRetry | Run the primary step loggic again immediately. If the step is an asynchronous step with queue data with a OMQ::QS_Waiting status, the queue data will be deleted immediately before the primary step logic is run again |
| OMQ::StatAsyncWaiting | For asynchronous steps only, do not run the primary step logic and keep the ASYNC-WAITING status. For non-asynchronous steps, raises an error and the return value is treated like ERROR |
| any other status | an error is raised and the return value is treated like ERROR |
Some step base classes have a validation() method that can be overridden where the validation logic can be defined. See the class documentation for the specific step class for more information on the signature and requirements for the validation method (if it's supported for the step type, not all step types support validation logic), and see Validation Code Return Value for a description of how the return value of this method affects workflow order processing.
validation trigger, the validation() method will never be executed, and the method body should remain empty (a default return statement may be necessary for syntactic correctness, however the method code will never be executed as long a Finite State Machine trigger exists for the method).validation() method for various step types can be accessed as finite state machine input data:
Asynchronous steps can define an end() method to process data submitted for the asynchronous workflow event. See the class documentation for the specific step class for more information on the end() method.
end trigger, the end() method will never be executed, and the method body should remain empty.array trigger, the array() method will never be executed, and the method body should remain empty (in Java, a default return null statement may be necessary for syntactic correctness, however the method code will never be executed as long a Finite State Machine trigger exists for the method).end() method for various step types can be accessed as finite state machine input data: